02. Custom Coadds from the Command Line (advanced)¶
Contact author: Aaron Meisner
Last verified to run: 05/14/2023
Targeted learning level: Advanced
Container size: large
Credit: This command line tutorial is based on the corresponding notebook tutorial by Melissa Graham. The command line approach is heavily influenced by Shenming Fu’s recipe for reducing DECam data with the Gen3 LSST Science Pipelines, which is in turn based on Lee Kelvin’s Merian processing instructions.
Introduction:
This tutorial shows how to use command line pipetask invocations to produce custom coadds from simulated single-exposure Rubin/LSST images. It is meant to parallel the corresponding Jupyter Notebook tutorial entitled Construct a Custom Coadded Image.
The peak memory of this custom coadd processing is between 8 and 9 GB, hence a large container is necessary.
This tutorial uses the Data Preview 0.2 (DP0.2) data set. This data set uses a subset of the DESC’s Data Challenge 2 (DC2) simulated images, which have been reprocessed by Rubin Observatory using Version 23 of the LSST Science Pipelines. More information about the simulated data can be found in the DESC’s DC2 paper and in the DP0.2 data release documentation.
A shell script version of this command line tutorial is also available.
WARNING: This custom coadd tutorial will only run with LSST Science Pipelines version Weekly 2022_40.
To find out which version of the LSST Science Pipelines you are using, look in the footer bar.
If you are using w_2022_40, you may proceed with executing this custom coadd tutorial.
- If you are not using
w_2022_40you must log out and start a new server: At top left in the menu bar choose File then Save All and Exit.
Re-enter the Notebook Aspect.
At the “Server Options” stage, under “Select uncached image (slower start)” choose
w_2022_40.Note that it might take a few minutes to start your server with an old image.
Why do I need to use an old image for this tutorial? In this tutorial and in the future with real LSST data, users will be able to recreate coadds starting with intermediate data products (the warps). On Feb 16 2023, as documented in the Major Updates Log for DP0.2 tutorials, the recommended image of the RSP at data.lsst.cloud was bumped from Weekly 2022_40 to Weekly 2023_07. However, the latest versions of the pipelines are not compatible with the intermediate data products of DP0.2, which were produced in early 2022. To update this tutorial to be able to use Weekly 2023_07, it would have to demonstrate how to recreate coadds starting with the raw data products. This is pedagogically undesirable because it does not accurately represent future workflows, which is the goal of DP0.2. Thus, it is recommended that delegates learn how to recreate coadds with Weekly 2022_40.
Step 1. Access the terminal and set up¶
1.0. Recall the scientific context motivating custom coadds
Per notebook 9a, a (hypothetical) supernova went off at (RA, Dec) = (55.745834, -32.269167) degrees on MJD = 60960. You wish to make a custom coadd of input DESC DC2 simulated exposures corresponding to a specific MJD range, nicknamed “Window1”: 60925 < MJD < 60955, roughly the month leading up to the explosion. The science goal is to search for any potential supernova precursor in the pre-explosion imaging, without contamination by the post-explosion transient.
1.1. Log in to the Notebook Aspect. The terminal is a subcomponent of the Notebook Aspect. Choose “w_2022_40” from the drop-down list under image and a “Large” container.
1.2. In the launcher window under “Other”, select the terminal.
1.3. Set up the Rubin/LSST software stack environment.
$ setup lsst_distrib
In this tutorial, the $ sign is used to indicate a command issued at the RSP terminal – do not include the $ in the command you issue.
1.4. Perform a command line verification that you are using the correct w_2022_40 version of the LSST Science Pipelines.
$ eups list lsst_distrib
g0b29ad24fb+9b30730ed8 current w_2022_40 setup
Step 2. Create your custom coaddition pipeline¶
As you saw in DP0.2 tutorial notebook 9a, you do not need to rerun the entire DP0.2 data processing in order to obtain custom coadds. You only need to run a subset of the tasks that make up step3 of the DP0.2 processing, where step3 refers to coadd-level processing. Specifically, you want to rerun only the makeWarp and assembleCoadd tasks.
The strategy for running these custom coadds via the command line is to start with the “Data Release Production” (DRP) pipeline used for DP0.2 processing and make relatively minor edits to isolate the specific makeWarp and assembleCoadd tasks of interest.
2.1. Inspect the DP0.2 YAML pipeline definition
Ensure that you’re in the working directory on RSP that you’ve chosen to be the place from which you will run the custom coadd processing. Let’s start by making a local copy of the DRP YAML pipeline definition file for DP0.2. It is conventional to put pipeline definition YAML files in a pipelines subdirectory, so let’s make one in your current working directory:
$ mkdir pipelines
Now make yourself a local copy of the full DP0.2 pipeline definition YAML:
$ pipetask build -p $DRP_PIPE_DIR/pipelines/LSSTCam-imSim/DRP-test-med-1.yaml \
--show pipeline > pipelines/MakeWarpAssembleCoadd.yaml
The above is the first of several pipetask commands used throughout this tutorial. pipetask commands are provided as part of the LSST Science Pipelines software stack and are used to build, visualize, and run processing pipelines from the terminal. When used as above with the --show pipeline option, pipetask build simply assembles and prints out the YAML pipeline definition specified via the -p argument.
Now let’s take a look at your newly created pipelines/MakeWarpAssembleCoadd.yaml pipeline definition file. There are multiple ways to view an ASCII (plain text) file such as pipelines/MakeWarpAssembleCoadd.yaml from a Linux terminal. Let’s use a program called head.
$ head -3151 pipelines/MakeWarpAssembleCoadd.yaml |tail -19
step3:
subset:
- writeObjectTable
- forcedPhotCoadd
- templateGen
- measure
- healSparsePropertyMaps
- mergeMeasurements
- consolidateObjectTable
- mergeDetections
- makeWarp
- deblend
- detection
- assembleCoadd
- selectGoodSeeingVisits
- transformObjectTable
description: |
Tasks that can be run together, but only after the 'step1' and 'step2'
subsets.
The specific arguments to head and tail here are used to only show the relevant lines of the full YAML file. Reading through other sections of pipelines/MakeWarpAssembleCoadd.yaml is left as an optional exercise for the learner.
2.2. Edit the YAML pipeline definition for making custom coadds
Now let’s edit your pipelines/MakeWarpAssembleCoadd.yaml pipeline definition file. There are multiple ways to edit a text file in a Linux environment, such as nano, emacs, and vim, all of which are available to you at the RSP terminal.
Using whichever text editor option you prefer, edit the step3 section of pipelines/MakeWarpAssembleCoadd.yaml so that only the makeWarp and assembleCoadd tasks remain. To do this, you should delete exactly 12 lines of YAML from within the step3 section, specifically the lines containing: - detection, - mergeDetections, - deblend, - measure, - mergeMeasurements, - forcedPhotCoadd, - transformObjectTable, - writeObjectTable, - consolidateObjectTable, - healSparsePropertyMaps, - selectGoodSeeingVisits, and - templateGen. Now the step3 YAML section shown above in Section 2.1 should look like this:
step3:
subset:
- makeWarp
- assembleCoadd
description: |
Tasks that can be run together, but only after the 'step1' and 'step2'
subsets.
Make sure to save your changes when you exit the text editor! Also make sure that you did not change any of the indentation in the pipelines/MakeWarpAssembleCoadd.yaml file, for the lines that remain. Note that the ordering of the - makeWarp and - assembleCoadd lines relative to each other does not matter.
Step 3. Show your pipeline and its configurations¶
3.1 Choose an output collection name/location
Some of the pipetask commands later in this tutorial require you to specify an output collection where your new coadds will eventually be written to. As described in the notebook version of tutorial 9a, you want to name your output collection as something like u/<Your User Name>/<Collection Identifier>. As a concrete example, throughout the rest of this tutorial u/$USER/custom_coadd_window1_cl00 is used as the collection name ($USER is a Linux environment variable that stores your RSP user name).
3.2 Build your custom-defined pipeline
Let’s not jump straight into running the pipeline, but rather start by checking whether the pipeline will first build. To build a pipeline, you use a command starting with pipetask build and specify the -p argument telling pipetask which specific YAML pipeline definition file you want it to build. If there are syntax or other errors in the YAML file’s pipeline definition, then pipetask build will fail with an error about the problem. If pipetask build succeeds, it will run without generating errors and print a YAML version of the pipeline to standard output. Here is the exact syntax:
$ pipetask build \
-p pipelines/MakeWarpAssembleCoadd.yaml#step3 \
--show pipeline
This is all one single terminal (shell) command, but spread out over three input lines using \ for line continuation. It would be entirely equivalent to run:
$ pipetask build -p pipelines/MakeWarpAssembleCoadd.yaml#step3 --show pipeline
The -p parameter of pipetask is short for --pipeline and it is critical that this parameter be specified as the new pipelines/MakeWarpAssembleCoadd.yaml file made in section 2.2. It is also critical that the -p argument contain the string #step3 appended at the end of the config file name. This is because you want to only run the coaddition step to make custom coadds. Run the above command. The full output is shown on a separate page for brevity.
pipetask --help provides documentation about pipetask, if you are (optionally) interested in learning more about pipetask and its command line options.
3.3 Customize and inspect the coaddition configurations
As mentioned in DP0.2 tutorial notebook 9a, there are a couple of specific coaddition configuration parameters that need to be set in order to accomplish the desired custom coaddition. In detail, the makeWarp Task needs two of its configuration parameters modified: doApplyFinalizedPsf and connections.visitSummary. First, let’s try an experiment of simply finding out what the default value of doApplyFinalizedPsf is, so that you can appreciate the results of having modified this parameteter later on. To view the configuration parameters, you need to use a pipetask run command, not a pipetask build command. The command used is shown here, and will be explained below:
$ pipetask run \
-b dp02 \
-p pipelines/MakeWarpAssembleCoadd.yaml#step3 \
--show config=makeWarp::doApplyFinalizedPsf
Notice that the -p parameter passed to pipetask has remained the same. But in order for pipetask run to operate, it also needs to know what Butler repository it’s dealing with. That’s why the -b dp02 argument has been added. dp02 is an alias that points to the S3 location of the DP0.2 Butler repository.
The final line merits further explanation. --show config tells the LSST pipelines not to actually run the pipeline, but rather to only show the configuration parameters, so that you can understand all the detailed choices being made by your processing, if desired. The last line would be valid as simply --show config. However, this would print out every single configuration parameter and its description – more than 1300 lines of printouts in total! Appending =<Task>::<Parameter> to --show config specifies exactly which parameter you want to be shown. In this case, it’s known from DP0.2 tutorial notebook 9a that you want to adjust the doApplyFinalizedPsf parameter of the makeWarp Task, hence why makeWarp::doApplyFinalizedPsf is appended to --show config.
Now let’s look at what happens when you run the above pipetask command:
$ pipetask run \
> -b dp02 \
> -p pipelines/MakeWarpAssembleCoadd.yaml#step3 \
> --show config=makeWarp::doApplyFinalizedPsf
Matching "doApplyFinalizedPsf" without regard to case (append :NOIGNORECASE to prevent this)
### Configuration for task `makeWarp'
# Whether to apply finalized psf models and aperture correction map.
config.doApplyFinalizedPsf=True
No quantum graph generated or pipeline executed. The --show option was given and all options were processed.
Ignore the lines about “No quantum graph” and “NOIGNORECASE” – for the present purposes, these can be considered non-fatal warnings. The line that starts with ### specificies that pipetask run is showing us a parameter of the makeWarp Task (as opposed to some other task, like assembleCoadd). The line that starts with # provides the plain English description of the parameter that you requested to be shown. The line following the plain English description of doApplyFinalizedPsf shows this parameter’s default value, which is a boolean equal to True. From DP0.2 tutorial notebook 9a, you know that it’s necessary to change doApplyFinalizedPsf to False i.e., the opposite of its default value. The following modified pipetask run command adds one extra -c input parameter for the custom doApplyFinalizedPsf setting:
$ pipetask run \
-b dp02 \
-p pipelines/MakeWarpAssembleCoadd.yaml#step3 \
-c makeWarp:doApplyFinalizedPsf=False \
--show config=makeWarp::doApplyFinalizedPsf
The penultimate line (-c makeWarp:doApplyFinalizedPsf=False \) is newly added. The -c parameter of pipetask run (note the lower case c) can be used to specify a desired value of a given parameter, with argument syntax of <Task>:<Parameter>=<Value>. In this case, the Task is makeWarp, the parameter is doApplyFinalizedPsf, and the desired value is False. Now find out if you succeeded in changing the configuration, by looking at the printouts generated from running the above command:
$ pipetask run \
> -b dp02 \
> -p pipelines/MakeWarpAssembleCoadd.yaml#step3 \
> -c makeWarp:doApplyFinalizedPsf=False \
> --show config=makeWarp::doApplyFinalizedPsf
Matching "doApplyFinalizedPsf" without regard to case (append :NOIGNORECASE to prevent this)
### Configuration for task `makeWarp'
# Whether to apply finalized psf models and aperture correction map.
config.doApplyFinalizedPsf=False
No quantum graph generated or pipeline executed. The --show option was given and all options were processed.
Notice that the printed configuration parameter value is indeed False i.e., not the default value…great! The second configuration parameter that you need to change can be passed to pipetask run in exactly the same way, by simply adding a second -c argument whose line in the full shell command looks like:
-c makeWarp:connections.visitSummary="visitSummary" \
Step 4. Explore and visualize the QuantumGraph¶
Before actually deploying the custom coaddition, let’s take some time to understand the QuantumGraph of the processing to be run. The QuantumGraph is a tool used by the LSST Science Pipelines to break a large processing into relatively “bite-sized” quanta and arrange these quanta into a sequence such that all inputs needed by a given quantum are available for the execution of that quantum. In the present case, you will not be doing an especially large processing, but for production deployments it makes sense to inspect and validate the QuantumGraph before proceeding straight to full-scale processing launch.
So far, you’ve seen pipetask build and pipetask run. For the QuantumGraph, you’ll use another pipetask variant, pipetask qgraph. pipetask qgraph determines the full list of quanta that your processing will entail, so at this stage it’s important to bring in the query constraints that specify what subset of DP0.2 will be analyzed. This information is already available from notebook tutorial 9a. In detail, you want to make a coadd only for patch=4431, tract=17 of the DC2 skyMap, and only using a particular set of 6 input exposures drawn from a desired temporal interval (visit = 919515, 924057, 924085, 924086, 929477, 930353). DP0.2 tutorial notebook 9a also provides a translation of these constraints into Butler query syntax as:
tract = 4431 AND patch = 17 AND visit in (919515,924057,924085,924086,929477,930353) AND skymap = 'DC2'
4.1 What are the quanta?
DP0.2 tutorial notebook 9a shows that the desired custom coaddition entails executing 7 quanta (6 for makeWarp – one per input exposure – plus one for assembleCoadd). Hopefully the command line version of this processing has the same number (and list) of quanta!
You can find out full details about all quanta with a pipetask qgraph command. Here’s the pipetask qgraph command:
$ pipetask qgraph \
-b dp02 \
-i 2.2i/runs/DP0.2 \
-p pipelines/MakeWarpAssembleCoadd.yaml#step3 \
-c makeWarp:doApplyFinalizedPsf=False \
-c makeWarp:connections.visitSummary="visitSummary" \
-d "tract = 4431 AND patch = 17 AND visit in (919515,924057,924085,924086,929477,930353) AND skymap = 'DC2'" \
--show graph
Be aware that this takes approximately 15 minutes to run.
No output might appear for most of that time, and it may seem as if nothing is happening.
If you are familiar with the top command, you’ll notice that running this in a new terminal will also seem to show no activity.
Note a few things about this command:
the command starts out with
pipetask qgraphrather thanpipetask runorpipetask build.the input data set
collectionwithin DP0.2 is specified via the argument-i 2.2i/runs/DP0.2. It’s necessary to know about the inputcollectionin order forpipetaskand Butler to figure out how many (and which) quanta are expected.The same custom pipeline as always is specified,
-p pipelines/MakeWarpAssembleCoadd.yaml#step3 \.-cis used twice, to override the default configuration parameter settings for bothdoApplyFinalizedPsfandconnections.visitSummary.The query string has speen specified via the
-dargument ofpipetask. Including this query constraint is really important – without it, Butler andpipetaskmight try to figure out the (huge) list of quanta for custom coaddition of the entire DP0.2 data set.
For brevity, the full output of running the above pipetask qgraph command is on a separate page.
As expected, there are 7 quanta (lines starting with Quantum N), where N runs from 0-5 (inclusive) for makeWarp and then there’s another N = 0 quantum for assembleCoadd. Note that the exact order in which the quanta get printed out is not always guaranteed to be the same.
4.2 Visualizing the QuantumGraph
In addition to generating and printing out the QuantumGraph you can also visualize the QuantumGraph as a “flowchart” style diagram. Perhaps counterintuitively, visualization of the QuantumGraph is performed with pipetask build rather than pipetask qgraph. This is because the QuantumGraph visualization depends only on the structure of the pipeline definition, and not on details of exactly which patches/tracts/exposures will be processed. For this same reason, you don’t need to specify all of the command line parameters (like the Butler query string) when generating the QuantumGraph visualization. The pipetask build command to generate the QuantumGraph visualization of your custom coadd processing is:
$ pipetask build \
-p pipelines/MakeWarpAssembleCoadd.yaml#step3 \
--pipeline-dot pipeline.dot; \
dot pipeline.dot -Tpdf > makeWarpAssembleCoadd.pdf
This command executes very fast (roughly 5 seconds), again because it is not performing any search through the DP0.2 data set for e.g., input exposures. The pipeline.dot output is essentially an intermediate temporary file which you may wish to delete. The PDF you make (shown below) can be opened by double clicking on its file name in the JupyterHub file browser.
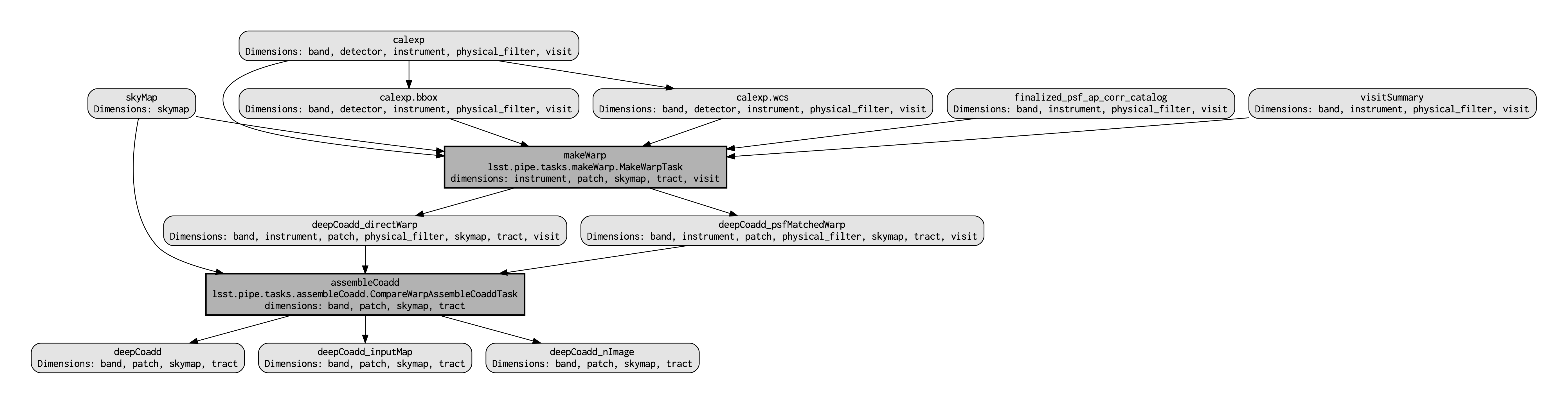
Light gray rectangles with rounded corners represent data, whereas darker gray rectangles with sharp corners represent pipeline Tasks. The arrows connecting the data and Tasks illustrate the data processing flow. The data processing starts at the top, with the calexp calibrated single-exposure images (also known as Processed Visit Images; PVIs). The makeWarp Task is applied to generate reprojected “warp” images from the various input calexp images, and finally the assembleCoadd Task combines the warps into deepCoadd coadded products (light gray boxes along the bottom row).
Step 5. Deploy your custom coadd processing¶
As you might guess, the custom coadd processing is run via the pipetask run command. Because this processing takes longer than prior steps, it’s worth adding a little bit of “infrastructure” around your pipetask run command to perform logging and timing. First, let’s start by making a directory into which you’ll send the log file of the coaddition processing:
$ export LOGDIR=logs
$ mkdir $LOGDIR
Now you have a directory called logs into which you can save the pipeline outputs printed when creating your custom coadds. Also, print out the processing’s start time at the very beginning and the time of completion at the very end, in both cases using the Linux date command. This will keep a record of how long your custom coadd processing took end-to-end. Send the date printouts both to the terminal and to the log file using the Linux tee command. Putting this all together, the final commands to generate your custom coadds are:
LOGFILE=$LOGDIR/makeWarpAssembleCoadd-logfile.log; \
date | tee $LOGFILE; \
pipetask --long-log --log-file $LOGFILE run --register-dataset-types \
-b dp02 \
-i 2.2i/runs/DP0.2 \
-o u/$USER/custom_coadd_window1_cl00 \
-p pipelines/MakeWarpAssembleCoadd.yaml#step3 \
-c makeWarp:doApplyFinalizedPsf=False \
-c makeWarp:connections.visitSummary="visitSummary" \
-d "tract = 4431 AND patch = 17 AND visit in (919515,924057,924085,924086,929477,930353) AND skymap = 'DC2'"; \
date | tee -a $LOGFILE
For users familiar with using shell scripts, you can save the above commands to a shell script file and then launch that shell script. You could name the shell script file, for instance, dp02_custom_coadd_1patch.sh. If you are not familiar with shell scripts, you can simply copy and paste the above commands into the terminal and hit the “return” key. The above commands take 30-35 minutes to run from start to finish. For brevity, the full output of running the above pipetask run script is on a separate page.
The last line (before the timestamp printout) says “Executed 7 quanta successfully, 0 failed and 0 remain out of total 7 quanta”. So that means every subcomponent of this custom coadd processing was successful.
Optional exercises for the learner¶
Retrieve and examine your custom coadd as described in DP0.2 tutorial notebook 9b. In section 1.3 of notebook 9b, set the name of the collection to include
custom_coadd_window1_cl00in place ofcustom_coadd_window1_test1, in order to use the custom coadd generated by this command line (cl) tutorial. The rest of DP0.2 tutorial notebook 9b can be executed as-is.Try applying further downstream processing steps to your custom coadd from the command line e.g., source detection run on the custom
deepCoaddproducts.Try modifying other configuration parameters for the
makeWarpand/orassembleCoaddtasks via thepipetask-cargument syntax.Try using the same two configuration parameter modifications as did this tutorial, but implementing them via a separate configuration (
.py) file, rather than via thepipetask-cargument (hint: to do this, you’d use the-Cargument forpipetask).Run the
pipetask qgraphcommand from section 4.1, but with the final line--show graphremoved. This still takes roughly 15 minutes, but prints out a much more concise summary listing only the total number of quanta to be executed, which should be 7.